
Golang Internals - 더 좋은 어셈블리 생성하기
Better x86 Assembly Generation from Go를 참고하여 작성한 글입니다.
이 포스트는 Go 어셈블러 생성에 대해 소개하는 글입니다.
Better x86 Assembly Generation from Go
by sDimitrios Arethas for the GopherCon 2019 Liveblog on July 25, 2019
Better x86 Assembly Generation from Go
소개
이 강연에서는 Go를 위한 초고속 어셈블리를 안전하게 작성할 수 있는 툴(avo)을 소개합니다.
Go 어셈블리와 Go 생태계에서 그 툴의 역할을 설명하고
어셈블리 개발을 위한 모범 사례를 홍보하며
코드 생성 도구가 대규모 어셈블리 프로젝트에서 복잡성을 관리하는 방법을 보여줍니다.
요약
Michael은 Go에서 x86 어셈블리를 작성하는 코드 생성 기술에 대한 사례를 만들었습니다.
Michael은 어셈블리, Go에서의 어셈블리, 어셈블리를 사용하는 사례 및 어셈블리를 사용하여
속도를 향상시키는 기술을 소개했습니다.
순수한 Go가 97% 의 사람들에게는 충분하지만, 나머지 3% 는 이 기술이 필요할 수 있습니다.
대표적인 예는 암호화, 시스템 호출 및 과학적 컴퓨팅(Scientific Computing)이 그 경우입니다.
Michael은 고성능 Go 어셈블리를 더 쉽게 작성할 수 있는 avo 라는 패키지를 소개합니다.
또 Go에서 어셈블리를 작성하면 어셈블리의 장점 외에도 고급 언어의 장점을 얻을 수 있다고 주장합니다.
(코드 가독성, 루프, 변수 및 함수 생성 기능, 매개 변수화 된 코드 생성 등)
마지막으로, 그는 avo의 미래에 대한 자신의 아이디어를 말하며 강연을 마칩니다.
머리말
이 강연은 기술적으로 복잡했고, 많은 세부 사항이 코드에 있었습니다.
정보는 강연 슬라이드에 제시되었으며 슬라이드를 전환하며 설명되었습니다.
라이브 블로깅으로는 설명을 어렵지만, 여기에서는 본질과 주요 포인트 위주로
설명하겠습니다.
참조할 강연 슬라이드는 여기에 영상은 여기에 있습니다.
Outline of the talk
- Go assembly primer
- 문제 설명(Problem Statement)
- 코드 생성(Code Generation)
- avo 라이브러리
- 예제
- Dot Product
- SHA-1
어셈블리 언어(Assembly Language)
어셈블리 언어란 아키텍처 수준에서 프로그래밍을 허용하는 저수준 언어입니다.
Michael은 어셈블리를 소프트웨어의 레이어에서 아래쪽으로의 터널 이라고 생각합니다.
어셈블리를 작성하는 경우 제일 밑바닥에 있는 것입니다.
어셈블리를 꼭 작성할 필요는 없습니다.
Rob Pike는 이렇게 말했습니다: “Cgo 어셈블리는 Go가 아닙니다. 안전하지 않은
패키지 어셈블리는 보장할 수 없습니다.”
또 Donald Knuth는 이렇게 말했습니다: “약 97%의 시간에서 조기 최적화(premature optimazation)는
모든 악의 근원입니다.”
그러나 Donald Knuth 인용문에서 포함되지 않은 일부는 “그러나 우리는 그 중요한 3% 의
기회를 포기해서는 안된다” 입니다.
중요한 3%
중요한 3%는 다음을 활용하는 것입니다:
- 컴파일러가 놓친 최적화
- 특별 하드웨어 명령들
일반적인 사용 사례는:
- 수학 계산 커널
- 시스템 호출
- 낮은 수준의 런타임 세부 정보
- 암호화
이 강연의 목적은 어셈블리를 사용하지 않는 것이 아니라, 만약 사용한다면,
안전하게 수행하고 이를 위해 가능한 한 많은 도구를 사용해야 한다는 것입니다.
Go Assembly Primer
package add
// Add x and y
func Add(x, y uint64) uint64 {
return x + y
}
다음 명령으로 Go 디스어셈블러를 실행할 수 있습니다.
$ go build -o add.a
$ go tool objdump add.a
그리고, 생성된 어셈블리 명령은 다음과 같습니다.
TEXT %22%22.Add(SB) gofile../Users/michaelmcloughlin/Dev...
add.go:5 0x2e7 488b442410 MOVQ 0x10(SP), AX
add.go:5 0x2e7 488b4c2408 MOVQ 0x8(SP), CX
add.go:5 0x2e7 4801c8 ADDQ CX, AX
add.go:5 0x2e7 4889442418 MOVQ AX, 0x18(SP)
add.go:5 0x2e7 c3 RET
맨 오른 쪽에 있는 열이 흥미로운 부분으로 우리에게 명령을 보여주고 있습니다.
package add
// Add x and y
func Add(x, y uint64) uint64
빌드 시스템이 이 버전의 (함수 본문없는) Add 함수를 보면, 다른 파일에 어셈블리 구현이
있을 것으로 예상합니다.
#include "textflag.h"
// func Add(x, y uint64) uint64
TEXT ·Add(SB), NOSPLIT, $0-24 <-- Declaration
MOVQ x+0(FP), AX <-- Read X from stack frame
MOVQ y+8(FP), CX <-- Read Y
ADDQ CX, AX <-- Add X and Y together
MOVQ AX, ret+16(FP) <-- Write return value
RET
어셈블리 정의는 TEXT 라인으로 시작합니다.
TEXT 라인의 24 값은 두 개의 64 bit(8 Byte) 값을 전달받고 64 bit 값을 반환하기
때문에 모두 24 Byte 가 됩니다.
그리고 나서 모든 함수는 MOV 명령으로 시작할 것이고, 모든 인자는 스택으로 전달됩니다.
문제 설명: 무엇이 잘못될 수 있을까요?
24,962: 표준 라이브러리의 x86 어셈블리 라인 수입니다.
다른 아키텍처를 포함한다면 이 숫자는 더 많을 것입니다.

Crypto는 라인 수가 가장 많습니다.
Crypto는 최고의 성능으로 완전한 정확성이 필요한 교차점에 있습니다.
에러가 발생한다면 심각한 보안 취약점으로 이어질 수 있기 때문입니다.
암호화 패키지의 일부 코드를 더 자세히 살펴보겠습니다.
(코드가 이해보다 Michael이 말하는 문제에 대한 느낌을 주기 위한 것입니다.)
openAVX2InternalLoop:
// Lets just say this spaghetti loop interleaves 2 quarter rounds with 3 poly multiplications
// Effectively per 512 bytes of stream we hash 480 bytes of ciphertext
polyAdd(0*8(inp)(itr1*1))
VPADDD BB0, AA0, AA0; VPADDD BB1, AA1, AA1; VPADDD BB2, AA2, AA2; VPADDD BB3, AA3, AA3
polyMulStage1_AVX2
VPXOR AA0, DD0, DD0; VPXOR AA1, DD1, DD1; VPXOR AA2, DD2, DD2; VPXOR AA3, DD3, DD3
VPSHUFB ·rol16<>(SB), DD0, DD0; VPSHUFB ·rol16<>(SB), DD1, DD1; VPSHUFB ·rol16<>(SB), DD2, DD2; VPSHUFB ·rol16<>(SB), DD3, DD3
polyMulStage2_AVX2
VPADDD DD0, CC0, CC0; VPADDD DD1, CC1, CC1; VPADDD DD2, CC2, CC2; VPADDD DD3, CC3, CC3
VPXOR CC0, BB0, BB0; VPXOR CC1, BB1, BB1; VPXOR CC2, BB2, BB2; VPXOR CC3, BB3, BB3
polyMulStage3_AVX2
VMOVDQA CC3, tmpStoreAVX2
VPSLLD $12, BB0, CC3; VPSRLD $20, BB0, BB0; VPXOR CC3, BB0, BB0
VPSLLD $12, BB1, CC3; VPSRLD $20, BB1, BB1; VPXOR CC3, BB1, BB1
VPSLLD $12, BB2, CC3; VPSRLD $20, BB2, BB2; VPXOR CC3, BB2, BB2
VPSLLD $12, BB3, CC3; VPSRLD $20, BB3, BB3; VPXOR CC3, BB3, BB3
VMOVDQA tmpStoreAVX2, CC3
polyMulReduceStage
VPADDD BB0, AA0, AA0; VPADDD BB1, AA1, AA1; VPADDD BB2, AA2, AA2; VPADDD BB3, AA3, AA3
VPXOR AA0, DD0, DD0; VPXOR AA1, DD1, DD1; VPXOR AA2, DD2, DD2; VPXOR AA3, DD3, DD3
VPSHUFB ·rol8<>(SB), DD0, DD0; VPSHUFB ·rol8<>(SB), DD1, DD1; VPSHUFB ·rol8<>(SB), DD2, DD2; VPSHUFB ·rol8<>(SB), DD3, DD3
polyAdd(2*8(inp)(itr1*1))
VPADDD DD0, CC0, CC0; VPADDD DD1, CC1, CC1; VPADDD DD2, CC2, CC2; VPADDD DD3, CC3, CC3
internal/x/.../chacha20poly1305_amd64.s lines 856-879 (go1.12)
“스파게티 루프”가 들어간 단어는 좋은 의미는 아닙니다.
Michael의 의견으로 한 번 코드를 작성했습니다.
코드 리뷰에서 이것을 제시했다면 어디서부터 시작 하시겠습니까?
이제 괜찮을까?
이 코드의 대부분은 암호화 및 성능 분야의 세계적인 전문가가 작성했으며
이러한 사람들이 Go 커뮤니티에 있다는 것은 행운입니다.
아마 괜찮겠지만, 검토해보면 좋을 것 같습니다.
TEXT p256SubInternal(SB),NOSPLIT,$0
XORQ mul0, mul0
SUBQ t0, acc4
SBBQ t1, acc5
SBBQ t2, acc6
SBBQ t3, acc7
SBBQ $0, mul0
MOVQ acc4, acc0
MOVQ acc5, acc1
MOVQ acc6, acc2
MOVQ acc7, acc3
ADDQ $-1, acc4
ADCQ p256const0<>(SB), acc5
ADCQ $0, acc6
ADCQ p256const1<>(SB), acc7
ADCQ $0, mul0
CMOVQNE acc0, acc4
CMOVQNE acc1, acc5
CMOVQNE acc2, acc6
CMOVQNE acc3, acc7
RET
crypto/elliptic/p256_asm_amd64.s lines 1300-1324 (94e44a9c8e)
위 코드는 표준 라이브러리의 일부입니다.

2년 전쯤 클라우드플레어가 캐리와 관련된 버그를 발견했는데, 40억분의 1로 발생하지만
클라우드플레어는 이를 경험할 정도로 규모가 컸습니다.

수정 사항은 단 5 줄입니다. 원래는 단지 호환성 이슈로 여겨졌습니다.

그러나 나중에 심각한 취약성으로 밝혀졌습니다.
이 중대한 에러는 안전한 정보를 누설하는 데 악용될 수 있었습니다.

그렇다면 이 8,000 개의 어셈블리 라인에 다른 것이 숨어 있을까요?
그리고 Go 팀 자체가 동의하여, 약 1 년 전에 그들은 Go Assembly 정책을 만들었습니다.
- 어셈블리가 아닌 Go 선호
- 어셈블리 사용 최소화
병목 현상으로 만 제한 - 근본 원인 설명
원인을 설명하는 커밋 메시지
향후 제거가 필요한 모든 정보 - 충분한 테스트
- 검토하기 쉬운 어셈블리 만들기

마지막 규칙은 Michael이 초점을 맞추고 싶은 것입니다.
“이 말을 들었을 때 나는 그것을 사명 선언문으로 삼았습니다.”
코드 생성은 사람들이 이런 복잡성을 관리하기 위해 수년 동안 사용해 온 도구입니다.
사람들이 컴파일러를 사용하는 데에는 이유가 있습니다.
어셈블리를 작성하기로 결정했다고 해서 이 모든 장점을 버릴 필요는 없습니다.
C 에는 Intristics 라는 것이 있는데, 이 함수는 각각 단일 명령어로 컴파일됩니다.
안타깝게도 Go에서는 이 작업을 수행할 수 없습니다.
Intristics 함수란 컴퓨터 소프트웨어의 컴파일러 이론에서 Intristics 함수(또는 builtin 함수)는
컴파일러에 의해 특별히 구현이 처리되는 함수(하위 루틴)입니다.
일반적으로, 인라인 함수와 유사하게, 본래의 함수 호출에 대해 자동 생성된 명령의 순서를
대체할 수 있습니다.
인라인 함수와는 달리 컴파일러는 내적 함수에 대한 친밀한 지식을 가지고 있으므로
상황에 맞춰 더 잘 통합하고 최적화할 수 있습니다.
어셈블리 언어에 고급 언어 기능이 추가되어 어셈블리에 if 문 및 루프의 개념이 있고
구조체가 추가된 높은 수준의 어셈블러도 있습니다.
OpenSSL 은 많은 어셈블리를 포함하는 또 다른 패키지이며, 매우 충격적인 언어 조합인
Perl을 사용합니다.
파이썬 기반의 고수준 어셈블러인 PeachPy라는 훌륭한 패키지도 있습니다.
하지만 Go 프로젝트에서 Python을 사용하는 것이 약간 복잡해서 Michael은 Go에 맞는 솔루션을
만들기 시작했습니다.
이 패키지를 사용하면 어셈블리를 작성하는 것처럼 느껴져야 하지만
실제로 Go 프로그램을 작성하는 것입니다.
avo 프로젝트의 잠재적인 목표(Non-goals)는:
- 컴파일러가 아닙니다: 어셈블리에 가까워야 합니다.
- 어셈블러가 아닙니다.
프로그래머가 완전한 제어권을 보유합니다.
어셈블리에서 수행할 수 있는 모든 작업을 이 패키지에서 수행할 수 있지만
목표는 지루함이나 반복을 제거하는 것입니다.
avo 프로그램은 Go 프로그램입니다.
함수, 루프, 조건을 사용하여 어셈블리를 구조화할 수 있습니다.
Michael이 생각하는 킬러 기능 중 하나는 레지스터 할당자를 포함하고 있다는 것입니다.
가상 레지스터를 사용하여 함수를 작성하면 avo가 물리적 레지스터를 할당합니다.
코드를 더 쉽게 읽을 수 있도록 의미있는 변수 이름을 사용할 수도 있습니다.
avo는 또한 메모리 오프셋을 자동으로 계산하는 세부 사항을 처리합니다.
또 Stub 파일(*.go)을 자동 생성하므로 Go 패키지에서 어셈블리 함수를 호출할 수 있습니다.
Stub이란, 소프트웨어 개발에서
다른 프로그래밍 기능을 위해 사용되는 코드 조각(토막)입니다.
Michael은 라이브러리를 설명합니다.
특히, avo를 사용하여 어셈블리를 생성하는 내적(Dot Product) 예제에서는
8 single-precision FMAs를 수행할 수 있는 VFMADD231PS 와 같은 "FMA"
(Fused-Multiply-Add) 명령과 같은 특수 하드웨어 명령을 활용할 수 있습니다.
마지막으로 SHA-1 예제는 약 1500 개의 어셈블리 라인으로 변환된 116 개의 avo 라인이며
avo와 같은 라이브러리를 사용하여 어셈블리를 더 쉽게 작성하고 읽고 유지 관리 할 수 있는
방법을 보여주었습니다.
Michael은 다음 목표와 방향으로 마무리합니다.
- 실제 프로젝트에서의 사용 방법
대규모 암호화 구현에서avo를 사용하여 단순화 할 수 있는 방법을 보여줍니다. - 더 많은 아키텍처 지원
avo를 어셈블러 자체로 만들기- 이러한 종류의 기술은 JIT 컴파일러에서 사용되므로 자연스러운 방향이 될 수 있습니다.
avo기반 라이브러리- avo/std/math/big
- avo/std/crypto
작별인사
어셈블리에 대해 배웠기를 바라며,
어셈블리가 더 이상 그렇게 무섭지 않기를 바라며,
프로젝트에서 사용한다면 avo를 사용해 보시길 바랍니다.
관련자료
Assembler pass
Compiler 구조
Rob Pike는 강연에서 Go 언어의 초기 버전에서 최근 구현에 이르기까지 컴파일러 아키텍처의
변경 사항에 대해 설명했습니다. 아래 그림은 컴파일러가 코드를 링크된(linked) 프로그램으로 변환하는
다양한 단계를 보여줍니다.
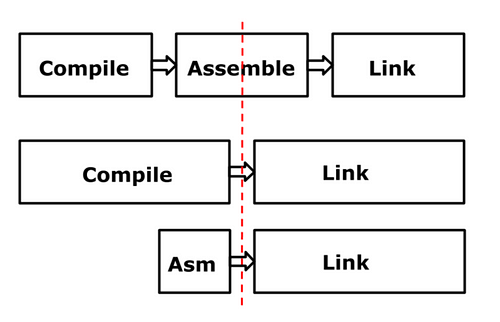
- 맨 위는 어셈블리 컴파일 코드를 사용하는 프로그램 방식입니다.
코드가 어셈블리로 컴파일되고 해당 어셈블리 코드가 링크됩니다.
gcc는 이 방식의 대표적인 컴파일러입니다.
빨간색 점선은 해당 지점에서 생성된 유사 명령어(Pseudo Instruction)의 바이너리 표현을 나타냅니다. -
다음은 Plan9 아키텍처가 코드에서 실행 가능한 바이너리를 만드는 방법을 나타냅니다.
Go 표준 라이브러리(STL)의 C 코드를 제거하기 위해, Go 1.3부터 Go 언어 설계자는 더 빠른 빌드를 위해
컴파일 속도를 희생했습니다.
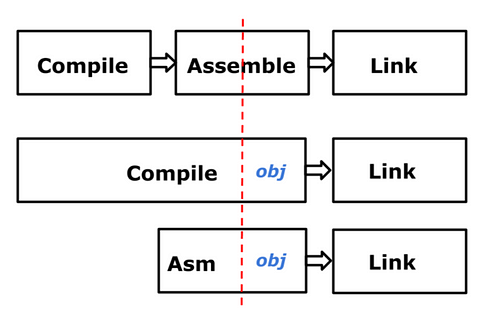
최신 아키텍처에서 맨 위의 프로세스는 기존 컴파일러가 수행하는 작업이고,
아래의 두 프로세스(Go의 컴파일 프로세스)에서 컴파일러는 기존 컴파일러가 수행하는
작업 뿐만 아니라 어셈블러의 역할도 수행합니다.
이제 컴파일 단계가 고수준 코드(Golang)와 어셈블리 생성을 모두 처리할 뿐만 아니라 obj 라는
중간 표현의 형태로 실제 명령어를 생성합니다. obj는 링커에 대한 실제 명령어를 생성하며
어셈블러 유형에도 영향을 받지 않습니다.
참고
댓글남기기